20211219-集成学习
集成学习 (Ensemble Learning)
集成学习本身并不是一个单独的机器学习算法,而是通过“博采众长”,即构建并结合多个机器学习器来完成学习任务。集成学习可用于:分类问题集成、回归问题集成、特征选取继承、异常点检测集成等任务。
1. 概述
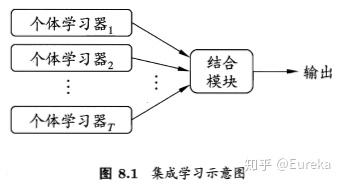
集成学习:对于给定的训练集,通过训练若干个个体学习器,通过特定的结合策略,最终形成一个强学习器。其中关键的问题:
如何得到若干个个体学习器;
“三个臭皮匠,顶个诸葛亮”。集成学习实际上大多是针对弱学习器(weak learner),即指泛化性能略优于随机猜测的学习器(如二分类问题中精度略高于50%的分类器)。
集成学习如何保证整体效果优于最好的学习器单独工作的效果?
个体学习器应该“好而不同”,即个体学习器要有一定的准确性,学习器既不能太差,且需要具有多样性。
根据个体学习器生成方式的不同,可将集成学习方法大致分为两类:
- 个体学习器之间存在强依赖关系,一系列学习器基本都需要串行生成的序列化方法,代表算法:boosting系列算法;
- 个体学习器之间不存在强依赖关系,一系列学习器可以并行生成,代表算法:bagging和随机森林(Random Forest)系列算法;
如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
平均法、投票法、学习法
2. 个体学习器
对既有的个体学习器,可以分成两种情况:
同质(homogeneous)集成:所有个体学习器均是同一种类的。同质集成中的个体学习器也称为为“基学习器”(base learner),相应的算法成为“基学习算法”。
举例:均为决策树个体学习器、或者都是神经网络个体学习器;
异质(heterogeneous)集成:所有的个体学习器不全是一个种类的。异质集成中的个体学习器称为“组件学习器”(component learner)或“个体学习器”。
举例:现有一个分类问题,对训练集采用支持向量机个体学习器,逻辑回归个体学习器和朴素贝叶斯个体学习器来学习,再通过某种结合策略来确定最终的分类强学习器。
3. Boosting
Boosting算法的工作机制
首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
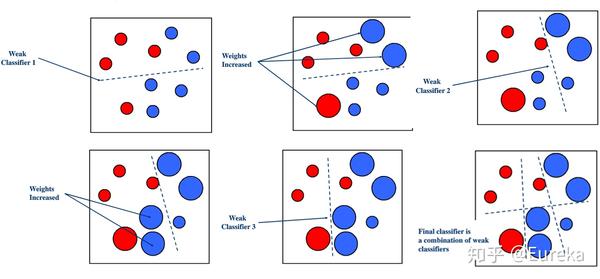
经典的Boosting算法
- AdaBoost算法
- 提升树Boosting tree系列算法:应用最广泛的是梯度提升树(Gradient Boosting Tree)。
4. Bagging
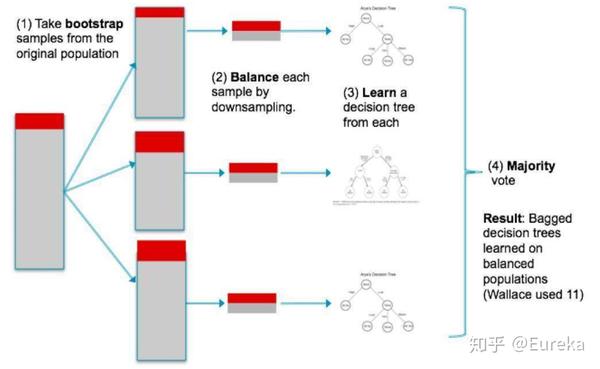
Bagging算法的工作机制
不同于boosting算法,它的弱学习器之间没有依赖关系,可以并行生成。bagging的个体弱学习器的训练集是通过随机采样得到的。通过3次的随机采样,我们就可以得到3个采样集,对于这3个采样集,我们可以分别独立的训练出3个弱学习器,再对这3个弱学习器通过集合策略来得到最终的强学习器。
随机森林(Random Forest,简称RF)是Bagging的一个扩展变体。其在以决策树作为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
5. Boosting和Bagging对比
| 算法 | Boosting | Bagging |
|---|---|---|
| 结构 | 串行 | 并行 |
| 训练集 | 依赖 | 独立 |
| 测试 | 需串行 | 可并行 |
| 作用 | 减小bias | 减小variance |
6. 结合策略
假设集成中包含 $T$ 个基学习器 $h_{1}, h_{2}, \ldots, h_{T}$,其中$h_i$在示例 $X$上的输出为 $h_i(x)$。那么对 $h_i$ 进行结合的常见策略有以下几种:
平均法
对于数值类的回归预测问题,通常使用的结合策略是平均法。
- 算术平均:$H(x)=\frac{1}{T} \sum_{1}^{T} h_{i}(x)$
- 加权平均:$H(x)=\sum_{1}^{T} w_{i} h_{i}(x)$,其中 $w_i$是个体学习器 $h_i$的权重
- 个体学习器的性能相差较大时用加权平均法,个体学习器性能相近时用简单平均法。
投票法
对于分类问题的预测,通常使用的结合策略是投票法。
- 相对多数投票法(Plurality Voting):即“少数服从多数”,即在$T$个弱学习器的对样本 $x$的预测结果中,数量最多的类别$c_i$为最终的分类类别。如果不止一个类别获得最高票,则随机选择一个做最终类别。
- 绝对多数投票法(Majority Voting):即“票需过半数”。在相对多数投票法的基础上,不光要求获得最高票,还要求票过半数。否则会拒绝预测。
- 加权投票法(Weighted Voting):和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
学习法
平均法和投票法思路简单,但是学习误差可能较大,于是产生了学习法。代表方法是stacking。当使用stacking的结合策略时, 我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
Stacking 就像是 Bagging的升级版,Bagging中的融合各个基础分类器是相同权重,而Stacking中则不同,Stacking中第二层学习的过程就是为了寻找合适的权重或者合适的组合方式。